
The persistence layer interacts with relational database and the service layer. It gets data from service layer, performs operations on database and sends back results to service layer. The code to interact with database is implemented in this layer. In this course, you will learn development of persistence layer using Spring ORM and Spring Data. concepts of persistence layer by developing a banking application named InfyBank containing multiple modules. One of the modules of this application is Customer module which has the following functionalities:
- Add customer
- Edit customer details
- View all customers
- Delete customers

Spring is a popular framework for enterprise application development. The developer can choose appropriate Spring modules such as Spring JDBC or Spring ORM to integrate with JPA, Hibernate etc. for implementing the data access layer of an enterprise application.
Spring further simplifies development of persistence layer using Spring Data, which is an umbrella project supporting both relational and non-relational databases effectively. It provides a consistent persistent layer code with minimal coding from the developer thereby eliminating a lot of developer effort.
In this course, you will learn how to develop persistence layer of an application using
- Spring ORM
- Spring Data
- Spring JDBC
Object-Relational Impedance Mismatch:
The JDBC code involves both Java objects (object model) and SQL queries (relational model). This makes it difficult to use because object model needs to be converted to relational model and vice versa. For example, for executing SQL select query the values present in Java object needs to be copied into SQL query but this conversion is not easy because of paradigm mismatch between object and relational model. This paradigm mismatch is called as Object-Relational Impedance Mismatch and it exposes following problems :
Problem of Granularity
This problem is that in object model, data can be present in more than one object but in relational model it is present in one table, i.e the object model is more granular than the relational model. For example, in object model you can have two separate classes, one for customer and the other for his address but in relational model, data about customer and his address can be stored in single table

Problem of Inheritance
This problem is that in object model, you can create classes having inheritance relationship but in relational model there is nothing that can define inheritance.

Problem of Identity
This problem is that the way in which equality of two objects is defined in object model is different for the way equality of two rows of a table is defined in relational model. For example, two rows in a table are same if they have same primary key values but two Java objects are equal if equals() method returns true.
Problem of Associations
This problem is that in object model, associations between objects is represented using references but in relational model, associations between tables is represented by foreign keys. Also, associations between objects can be unidirectional or bidirectional. However, in associations between tables there is no way to store information about directionality of relationship.

Problem of Data Navigation
This problem is that the way you access data in object model is different from the way you do it in a relational database. For example, in Java you navigate across association relationships using dot(.) operator but in relational model you navigate across related tables using joins.
To handle these problems, a technique called as Object-Relational Mapping (ORM) was introduced. It handles object relational impedance mismatch by providing a way to map Java objects to tables so that object model can be automatically translated to relation model and vice versa, allowing developers to focus only on the object model.
Object Relational Mapping (ORM) - Introduction
Object Relational Mapping (ORM) is a technique or design pattern, which maps an object model with the relational model. It has the following features:
- It resolves object-relational impedance mismatch by mapping
- Java classes to tables in the database
- Instance variables to columns of a table
- Objects to rows in the table
- It helps the developer to get rid of SQL queries so that they can concentrate on the business logic which leads to faster development of the application.
- It is database independent. All database vendors provide support for ORM. Hence, the application becomes portable without worrying about the underlying database.
To use ORM in Java applications, Java Persistence API (JPA) specification is used. It has many implementations such as Hibernate, OpenJPA, TopLink, EclipseLink, etc. In this course we will use Hibernate implementation.
Java Persistence API (JPA)
The Java Persistence API (JPA) is a specification that defines standard for using object relational mapping (ORM) in Java applications for interacting with relational database. It provides :
- API to map classes with tables
- API for performing CRUD operations
- Java Persistence Query Language (JPQL), a querying language for fetching data from database
- Criteria API which uses object graph to fetch data from database
There are multiple providers available in market which provides implementation of JPA specification such as EclipseLink, OpenJPA, Hibernate, etc.
Defining Entirty Class
The classes which are mapped to a table and whose instance represents a row in table are entity classes. JPA provides annotations to create entity classes which are present in the javax.persistence package.
- @Entity : It specifies that the Java class is an entity class.
- @Id : Every object of entity class must have an attribute which uniquely identifies it. This is called as primary key attribute or identifier. Usually, it is the attribute mapped to the primary key column of table. It is specified using @Id annotation.
- @Table : It specifies the table with which entity class is mapped. By default, entity class is mapped with a table which has same name as the class name. If entity class has to be mapped with a table whose name is different from class name then, this annotation is used. For example, if CustomerDetails class has to be mapped with customer table then the annotation needs to be used
- @Column : It specifies the name of column in table with which attribute in entity class is mapped. By default, column name is mapped with a column which has same name as the attribute name. If attribute name is different from column name, then this annotation is used. For example, if customerId is to be mapped to customer_id column, then the annotation needs to be used
- @Transient : It specifies the attributes which are not stored in table.
Consider the CUSTOMER table given below and its corresponding Customer entity class :

@Entity
public class Customer {
@Id
@Column(name="customer_id")
private Integer customerId;
@Column(name="email_id")
private String emailId;
private String name;
@Column(name="date_of_birth")
private LocalDate dateOfBirth;
//getter and setters
}
Sometimes, entity class has a reference of enum and if you want to persist it, you can use @Enumerated annotation. For example, consider the following Java class which as a reference to CustomerType enum and you have to map it to CUSTOMER table in the database:
public class Customer {
private Integer customerId;
private String emailId;
private String name;
private LocalDate dateOfBirth;
private CustomerType customerType;
//getters and setters
}
public enum CustomerType{
SILVER,GOLD,PLATINUM;
}

@Entity
public class Customer {
@Id
@Column(name="customer_id")
private Integer customerId;
@Column(name="email_id")
private String emailId;
private String name;
@Column(name="date_of_birth")
private LocalDate dateOfBirth;
@Enumerated(EnumType.STRING)
private CustomerType customerType;
//getters and setters
}
CustomerType is annotated with @Enumerated annotation. The EnumType property is used to specify how the enum should be persisted in the database.
The possible values of EnumType property are as follows:
- @Enumerated(EnumType.STRING) specifies that the enum will be written and read from the corresponding database column as a String. So, customerType set to SILVER will be persisted as SILVER.
- @Enumerated(EnumType.ORDINAL) specifies that the enum will be persisted as an integer value. So, customerType set to SILVER will be persisted as 0 and customerType set to GOLD will be persisted as 1. The default is EnumType.ORDINAL.
Best Practices in defining an Entity class
One of the best practices that should be followed while creating an Entity class is:
Override the equals() and hashCode() methods in the entity classes
The Customer entity class implementation shown to you is sufficient to map it to CUSTOMER table but it is considered as a good practice to override the equals() and hashCode() methods in the entity classes
@Entity
public class Customer {
@Id
@Column(name="customer_id")
private Integer customerId;
@Column(name="email_id")
private String emailId;
private String name;
@Column(name="date_of_birth")
private LocalDate dateOfBirth;
@Enumerated(EnumType.STRING)
private CustomerType customerType
//getter and setters
@Override
public int hashCode() {
final int prime = 31;int result = 1;result = prime * result + ((this.getCustomerId() == null) ? 0 : this.getCustomerId().hashCode());return result;
}
@Override
public boolean equals(Object obj) {
@Override
public boolean equals(Object obj) {
if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;Customer other = (Customer) obj;if (this.getCustomerId() == null) {
if (other.getCustomerId() != null)return false;
}
}
This is because each instance of an entity class represents a row in database and in real time, you may have many objects of this class. So, you need to differentiate one object from the other. JPA ensures that there is a unique instance for each row of the database but if you want to store the objects in a Set, then you need to override equals() and hashCode() methods.
Best practice :
Avoid database tables associated to more than one entity, i.e., one single table in the database should be associated with only one entity
While mapping entity classes and the database tables, it is advised to avoid database tables associated to more than one Entity. i.e; one single table in the database should be associated with one single entity.
What can be the possible reason for this?
Consider a scenario where two entities are mapped to the same database table.
The problem arises because Hibernate doesn’t know which entity represent the same database record. The disadvantage here is that, developers have to make sure they don’t fetch more than one entity type for the same database table record. Otherwise, this can cause inconsistencies when flushing the persistence context. Hibernate doesn’t refresh any of these entities if we update the other one as it handles them independently.
Every entity object has a state in relation to both persistence context and the database. Every entity object has different states depending on its relationship with persistence context. This defines the life cycle of an entity object. The different states of an entity object during its life cycle are as follows:
- New/Transient State : A newly created entity object which has no persistence context associated with it and having no row associated with it in a table in database is said to be in new or transient state.
- Managed/Persistent State : An entity object which has a persistence context and an identifier value associated with it is said to be in managed or persistent state. It may or may not have a row associated with it in a table.
- Removed State : An entity object which has a row associated with it in a table and associated with a persistence context, but marked for deletion from the database is said to be in removed state.
- Detached State : An entity object which is no longer associated with a persistence context with which it was previously associated with it is said to be in detached state. This usually happens when session gets closed or the object was evicted from the persistence context.
Method in JPA
- void persist(Object entity) - It makes a new entity object managed. When transaction is committed, a new row will be inserted in the database.
- find(Class entityClass, Object primaryKey) - It searches the database table based on the primaryKey and returns the row as an object of entity class. It returns null if no row is present in the database. It returns the entity object in the managed state.
- void remove(Object entity) - It changes the state of entity object from managed to removed and object gets deleted from the database when transaction is committed.
- void detach(Object entity) - It detaches the given entity from the persistence context associated with it and changes its state to detached.
Demo:
Using Spring Initializr, create a Spring Boot project with following specifications:
- Spring Boot Version: 2.3.1 (The version keeps on changing, always choose the latest release)
- Group: com.infy
- Artifact: Demo_SpringOrmCRUD
- Name: Demo_SpringOrmCRUD
- Package name: com.infy
- Java Version: 11
- Dependencies: Spring Data JPA and MySQL Driver
Read Operation Using JPA - DemoSpringORMfetch.zip
@Repository(value = "customerRepository")
public class CustomerRepositoryImpl implements CustomerRepository{
@PersistenceContext
private EntityManager entityManager;
@Override
public CustomerDTO getCustomer(Integer customerId) {
CustomerDTO customerDTO=null;
Customer customer = entityManager.find(Customer.class, customerId);
if(customer!=null){
customerDTO=new CustomerDTO();
customerDTO.setCustomerId(customer.getCustomerId());
customerDTO.setDateOfBirth(customer.getDateOfBirth());
customerDTO.setEmailId(customer.getEmailId());
customerDTO.setName(customer.getName());
customerDTO.setCustomerType(customer.getCustomerType());
}
return customerDTO;
}

Create Operation Using JPA - DemoSpringORMcreate.zip
@Repository(value = "customerRepository")
public class CustomerRepositoryImpl implements CustomerRepository{
@PersistenceContext
private EntityManager entityManager;
@Override
public void addCustomer(CustomerDTO customerDTO) {
Customer customer=new Customer();
customer.setCustomerId(customerDTO.getCustomerId());
customer.setDateOfBirth(customerDTO.getDateOfBirth());
customer.setEmailId(customerDTO.getEmailId());
customer.setName(customerDTO.getName());
customer.setCustomerType(customerDTO.getCustomerType());
entityManager.persist(customer);
}
}
- A newly created Customer object will be in NEW/TRANSIENT state.
- The persist() method is invoked to associate a Customer object with persistence context and it changes its state from NEW to MANAGED.
- The values present in entity object will be inserted in database when the transaction is committed. If the table already has customer details with the same customerId, then EntityExistsException will be thrown.

This exception is thrown because every DML operation needs a database transaction and we have not created any.
To create a database transaction, annotate CustomerServiceImpl class with @Transactional
To create a database transaction, annotate CustomerServiceImpl class with @Transactional

Ways of transaction management in Spring
Transaction management is important while writing persistence layer code for maintaining database integrity and consistency. If transaction management is not done properly, database may get corrupted and left in an inconsistent state. This can be done in following two ways:
1. Programmatic transaction management : In programmatic transaction management, the following code to manage transactions is written in each method which needs transaction:Transaction transaction = entityManager.getTransaction()
try{
try{
transaction.begin();// business logictransaction.commit();
}catch(Exception exception){
transaction.rollback();throw exception;
}
this code is repeated in each of the methods which need transaction, this way of transaction management is not preferred.
2. Declarative transaction management : In declarative transaction management code to manage transactions is separated from your business logic. This makes transaction management easier. So this way is usually preferred for transaction management. This is done using @Transactional annotation
You can annotate a class or its transactional methods with @Transactional annotation. When it is used at class level, then all its public methods become transactional. Otherwise, only those methods of the class which are annotated with this annotation becomes transactional. If this annotation is placed at class level as well as method level then method level definition overrides the class definition.
@Service(value = "customerService")
@Transactionalpublic class CustomerServiceImpl implements CustomerService {
@Autowired
private CustomerDao customerDao;
//rest of the code
}
The attributes of @Transactional annotation has default values. You can change these values according to the requirement of your application. The default values of its different attributes are as follows:
- isolation = DEFAULT
- propagation = REQUIRED
- timeout = TIMEOUT_DEFAULT
- readOnly =false
- rollbackFor = RuntimeException or its subclasses
- noRollbackFor = Exception or its subclasses
You can use this annotation with repository or service classes but it is a good practice to use it with service classes. This is because service class may call methods of different repository classes to perform database operations and if any of these methods throw exception, you may end up with inconsistent database state. So, annotating service class with this annotation prevents these type of situations
Update Operation Using JPA
@Override
public Integer updateCustomer(Integer customerId, String emailId) {
public Integer updateCustomer(Integer customerId, String emailId) {
Integer customerIdReturned = null;Customer customer = entityManager.find(Customer.class, customerId);customer.setEmailId(emailId);customerIdReturned = customer.getCustomerId();return customerIdReturned;
}


- The details of the customer whose emailId has to be updated is fetched using find() method and then emailId of customer is updated with new values.
- The EntityManager automatically detects the changes and when transaction is committed, the database gets updated.
- The entity object remains in managed state during this operation.

Delete Operation USing JPA
@Repository(value = "customerRepository")
public class CustomerRepositoryImpl implements CustomerRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public Integer deleteCustomer(Integer customerId) {
Customer customer = entityManager.find(Customer.class, customerId);
entityManager.remove(customer);
Integer customerIdReturned = customer.getCustomerId();
return customerIdReturned;
}
}
- The details of the customer which has to be deleted is fetched using find() method.
- The remove() method is invoked using Customer object. This changes the state of entity object from managed to removed.
- The customer details will be deleted from the table when the transaction is committed.

Some of the best practices that should be followed while developing Persistence Layer are as follows:
- Manage Transactions Only in Service Layer
As we have discussed previously, @Transactional annotation is used for classes or it's methods which interact with the Persistence Layer for fetching/persisting data into the database. Hence, by this definition, any class or it's method can interact with the Persistence Layer regardless of the class being a Service Layer implementation or not.
However, in a Spring-based application, classes implementing Service Layer are specifically assigned for interaction with Persistence Layer. Hence, it is a best practice to annotate only Service Layer classes and/or it's methods with @Transactional and interact with the Persistence Layer.
- Abstract Persistence Layer from Service Layer
As we have observed in the demos previously, none of the business logic are present in the Persistence Layer classes. We can also definitively conclude that both Service Layer and Persistence Layer are two separate entities.
Keeping business logic in classes implementing Persistence Layer is never a good practice because:
Ideally, the Service Layer must not know the functionalities of Persistence Layer. Hence, a layer of abstraction is essential.
Coupling of Persistence Layer with Service Layer becomes a nightmare when the application needs to switch to a different database. Hence, having no business logic in Persistence Layer helps in migrating the application over different databases.
3 . @PersistenceContext
@PersistenceContext should be preferred over @Autowired for injecting EntityManager
Why should @PersistenceContext should be used?
When multiple clients call the application, each call creates a unique thread.
Persistence Context is specifically designed so as to create unique EntityManager for every thread whereas Autowired creates the same Entity Manager for all the threads. This can become a design flaw as multiple clients may access the same entity.
Advantages :
Spring-ORM provides support for many persistence technologies such as JPA, Hibernate, etc. It provides easy integration of these technologies with Spring and provides following benefits in development of persistence layer:
1. Easy testing
The DAO layer code has many dependencies such EntityManager instance, JDBC DataSource instance, transaction managers etc. Using Spring’s dependency injection, you can easily replace these dependencies which makes testing of DAO layer code easy and possible without deploying it on server.
2. Common data access exceptions
The exceptions thrown from DAO layer are persistence technology specific. This means that if you change persistence technology then service layer code for handling exception needs to be changed. But by annotating DAO class with @Repository annotation the exceptions specific to underlying persistence technology are translated to Spring’s DataAccessException. So even if you change persistence technology the DAO layer always throws DataAccessException due to exception translation and thus service layer code need not to be changed. So, you can use different persistence technology in DAO layer.
3. Automatic resource management
Spring automatically manages resources such as EntityManager instance, DataSource instance and injects it into DAO layer beans and so developer need not to manage it manually.
4. Easy transaction management
Spring provide support for transaction management either declaratively or programatically without depending on persistence technology used.
Introdution to JPQL
Consider the following requirements of the InfyBank application:
- An admin should be able to search customers based on their date of birth
- An admin should be able to update the customer details by searching based on the address
- An admin should be able to find average balance of the customers of the branch
To implement the above requirements, you need to search or update customer details based on non-primary key values. So, you cannot use find() method. To handle these kind of requirements, JPA provides a query language called as Java Persistence Query Language (JPQL). These queries are defined using entity classes and its attributes instead of tables and columns. This makes it easy for Java developers to use it. But since database uses SQL, JPA implementations translate the JPQL query into SQL using query translator.
Query interface
To create and execute JPQL queries, JPA provides Query interface. An object of Query interface is created through EntityManager interface using createQuery method
Query query = entityManager.createQuery("SELECT c FROM Customer c");
where SELECT c from CustomerEntity c is a JPQL query.
This interface provides following methods to execute a query:
- List getResultList() : This method executes select queries and returns a List of results. It throws IllegalStateException if called for update and delete queries.
- Integer executeUpdate() : This method executes update and delete queries. It returns the number of rows updated or deleted. It throws IllegalStateException if called for select queries.
- Object getSingleResult() : This method executes select query which returns a single result. If no result available it throws NoResultException. It throws NonUniqueResultException if query returns more than one results and IllegalStateException if called for update and delete queries.
Selection – The SELECT clause
Fetching all columns
Consider a requirement where a teller should be able to view the details of all the customers.
To implement this requirement, you can create a JPQL query using SELECT and FROM clause. The SELECT clause defines the result type of query and FROM clause specifies the entities from which data has to be fetched. If Customer entity class is mapped to Customer table, then following JPQL query fetches details of all the customers :
SELECT c FROM Customer c
In the above JPQL query, c is an alias for Customer and is also known as identification variable. In SELECT clause only c is used which means that the result type of query is the Customer, so this query on execution gives List<Customer>. The following code snipped creates Query object using above query and executes itQuery query = entityManager.createQuery("SELECT c FROM Customer c");
List<Customer> customers = query.getResultList();
List<Customer> customers = query.getResultList();
If query returns a java.util.Collection, which allows duplicates, you must specify the DISTINCT keyword to eliminate duplicates.
List<String> customers = query.getResultList();
Consider one more requirement where a teller should be able to view the names and dates of birth of all the customers.
Query query = entityManager.createQuery("SELECT c.customerName, c.dateOfBirth FROM Customer c");
List<Object[]> customers = query.getResultList();
Avoid unnecessary columns that are not required
You have seen in the previous examples that the SELECT clause used are simple in terms of the data being fetched.
Such a usage of simple SELECT clause, avoiding unnecessary columns that are not required, is considered as a good practice.
What can be the reason for this?
Complex select clauses with many columns can be difficult to read and also in identifying the relevant columns to be retrieved. Also a query that retrieves many columns can potentially cause performance problems specially when the execution of the query returns a large result sets.
To implement this user story, you need to filter entities based on customerId. This can be done using the WHERE clause. The following JPQL query fetches details of a customer whose customerId is 1002:
SELECT c FROM Customer c WHERE c.customerId = 1002;
In the above query, customerId is hardcoded. But you can also define input parameters for a query that can be bound with values. There are following two ways using which you can define these parameters:
SELECT c FROM Customer c WHERE c.customerId = :customerId;
Before executing above query values for input parameters must be set. This can be done using setParameter() method of Query interface
List<Customer> getCustomerDetails(Integer customerId){
Fetching Single Column
Consider another requirement where a teller should be able to view the names of all the customers.
If Customer entity class is mapped to Customer table, and it has an attribute customerName then this requirement can be implemented using following JPQL query:
SELECT c.customerName FROM Customer c
In the above query, you can access the customerName attribute of Customer using identification variable c and dot (.) operator. Since customerName is of type String, this query will return a List<String>. The following code snippet creates Query object using above JPQL query and executes it:
Query query = entityManager.createQuery("SELECT c.customerName FROM Customer c");List<String> customers = query.getResultList();
Fetching multiple but not all columns
Consider one more requirement where a teller should be able to view the names and dates of birth of all the customers.
If Customer entity class is mapped to Customer table and it has attributes customerName and dateOfBirth then this requirement can be implemented using following JPQL query
SELECT c.customerName, c.dateOfBirth FROM Customer c
In this case query will return a List<Object[]>. In this list each element is an Object[] which has two values. The first value is customerName and second is dateOfBirth of each customer. The following code snippet creates Query object using above JPQL query and executes it:Query query = entityManager.createQuery("SELECT c.customerName, c.dateOfBirth FROM Customer c");
List<Object[]> customers = query.getResultList();
Best Practices
A best practice that should be followed while implementing SELECT clause is:Avoid unnecessary columns that are not required
You have seen in the previous examples that the SELECT clause used are simple in terms of the data being fetched.
Such a usage of simple SELECT clause, avoiding unnecessary columns that are not required, is considered as a good practice.
What can be the reason for this?
Complex select clauses with many columns can be difficult to read and also in identifying the relevant columns to be retrieved. Also a query that retrieves many columns can potentially cause performance problems specially when the execution of the query returns a large result sets.
Restriction - WHERE Clause
Consider a requirement where a teller should be able to view the details of a customer based on customerId.To implement this user story, you need to filter entities based on customerId. This can be done using the WHERE clause. The following JPQL query fetches details of a customer whose customerId is 1002:
SELECT c FROM Customer c WHERE c.customerId = 1002;
In the above query, customerId is hardcoded. But you can also define input parameters for a query that can be bound with values. There are following two ways using which you can define these parameters:
1. Named Parameters
The input parameters which are prefixed with a colon (:) are called as named parameters. For example, in following JPQL query: customerId is a named parameter:SELECT c FROM Customer c WHERE c.customerId = :customerId;
Before executing above query values for input parameters must be set. This can be done using setParameter() method of Query interface
List<Customer> getCustomerDetails(Integer customerId){
Query query = entityManager.createQuery("SELECT c FROM Customer c WHERE c.customerId = :customerId";
query.setParmeter("customerId",customerId);
List results = query.getResultList(;
//rest of the code
}
2. Positional Parameters
The input parameters which are prefixed with a question mark (?) followed the numeric position of the parameter in the query starting from 1 are called as positional parameters. For example, in following JPQL query customerId is mentioned as a positional parameter:
select c FROM Customer c WHERE c.customerId = ?1;
The values for positional parameters can be set by calling the setParameter() method
List<Customer> getCustomerDetails(Integer customerId){
Query query = entityManager.createQuery("SELECT c FROM Customer c WHERE c.customerId = ?1";query.setParmeter(1,customerId);List results = query.getResultList();//rest of the code
}
Operations
JPQL provides operators for performing comparison which is similar to comparison operators of SQL. These operators can be combined with AND, OR and NOT logical operators to create complex expressions.
SELECT c FROM Customer c WHERE c.customerId = 1002
SELECT c FROM Customer c WHERE c.city != 'Seattle'
SELECT c FROM Customer c WHERE c.dateOfBirth > '1-Jan-1980'
SELECT c FROM Customer c WHERE c.dateOfBirth >= '1-Jan-1980'
SELECT c FROM Customer c WHERE c.dateOfBirth < '1-Jan-1980'
SELECT c FROM Customer c WHERE c.dateOfBirth <= '1-Jan-1980'
SELECT c FROM Customer c WHERE c.dateOfBirth BETWEEN '1-Jan-1975' AND '1-Jan-1980'
SELECT c FROM Customer c WHERE c.name LIKE 'R%'
SELECT c FROM Customer c WHERE c.emailId IS NULL
SELECT c FROM Customer c WHERE c.city IN ('Seattle','Vancouver')
SELECT c FROM Customer c WHERE c.loans IS EMPTY
SELECT c FROM Customer c WHERE c.loans IS NOT EMPTY
SELECT c FROM Customer c WHERE SIZE(c.loans) > 2
JPQL Aggregate Funtion
SELECT AVG(a.balance) FROM Account a
SELECT SUM(a.balance) FROM Account a
SELECT COUNT(a) FROM Account a
SELECT MIN(a.balance) FROM Account a
SELECT MAX(a.balance) FROM Account a
JPQL String Functions

JPQL Grouping
SELECT c.city, COUNT(c) FROM Customer c GROUP BY c.city
SELECT c.city, COUNT(c) FROM Customer c GROUP BY c.city HAVING c.city IN ('Seatle','Vancouver')
SELECT c FROM Customer c ORDER BY c.name ASC/DESC
Update Queries
For performing update operation, JPQL provides UPDATE statement. The following query updates the city of a customer whose customerId is 1002 to "Seatle":
UPDATE Customer c SET c.city = 'Seatle' where c.customerId = 1002;
An UPDATE statement is executed using the executeUpdate() methodQuery query = entityManager.createQuery("UPDATE Customer c SET c.city = 'Seatle' where c.customerId = 1002");
int updatedEntities = query.executeUpdate();
It returns the number of entities affected by the operation.
Delete Queries
For performing delete operation, JPQL provides DELETE statement. The following query deletes all the inactive accounts:Query query = entityManager.createQuery("DELETE FROM Account a WHERE a.status = 'INACTIVE'");
int updatedEntities = query.executeUpdate();
int updatedEntities = query.executeUpdate();
Delete queries do not follow cascade rules even if an entity has association relationship with other entities and cascade remove is enabled i.e only entities of the type mentioned in query and its sub-classes will be removed.
Introduction to Spring Data
To develop the persistence layer using Spring ORM, you would have first created entity classes similar to the CustomerEntity entity class given by
@Entity
public class Customer{
@Id
private Integer customerId;
private String emailId;
private String name;
private LocalDate dateOfBirth;
//getter and setter methods
}
After creating entity class, you would have implemented classes similar to CustomerRepositoryImpl class given below to perform basic CRUD operations.
@Repositorypublic class CustomerRepositoryImpl implements CustomerRepository{
@PersistenceContextprivate EntityManager entityManager;//add customer detailspublic void addCustomer(CustomerDTO customerDTO) {
Customer entity=new Customer();entity.setCustomerId(customerDTO.getCustomerId());entity.setDateOfBirth(customerDTO.getDateOfBirth());entity.setEmailId(customerDTO.getEmailId())entity.setName(customerDTO.getName());entityManager.persist(entity);
}//fetches customer details based on customerIdpublic CustomerDTO getCustomer(Integer customerId) throws Exception {
CustomerDTO customerDTO=null;Customer customer = entityManager.find(Customer.class, customerId);if(customer!=null){
customerDTO = new CustomerDTO();customerDTO.setCustomerId(customer.getCustomerId());customerDTO.setDateOfBirth(customer.getDateOfBirth());customerDTO.setEmailId(customer.getEmailId());customerDTO.setName(customer.getName());
}return customer;
}//update customer email addresspublic void updateCustomer(Integer customerId, String newEmailId) throws Exception {
Customer customer = entityManager.find(Customer.class, customerId);customer.setEmailId(newEmailId);
}
//delete customer detail
public Integer deleteCustomer(Integer customerId) throws Exception {
Customer customer = entityManager.find(Customer.class, customerId);if(customer!=null){entityManager.remove(customer);}
}
}

CrudRepository Ref
public class DemoSpringDataApplication implements CommandLineRunner {
Now suppose, if you also have Product entity, then you have to implement ProductRepositoryImpl class having similar code as that of CustomerRepositoryImpl. In case of real life enterprise applications, there will be many entity classes and for each entity class you have to write similar code. This means that you have to write lot of repetitive code to perform basic CRUD operations. This makes development of persistence layer time consuming which reduces the productivity of a developer.
So, it would be very beneficial if there exists a framework which can reduce the need of implementing similar type of repetitive code to perform CRUD operations thereby reducing the time taken and effort of developer.
Such a framework which helps in easy and fast development of persistence layer is Spring Data.
Spring Data provides repositories which are interfaces associated with entity and provide different methods for performing database operations. Spring automatically generates the implementation class of these interfaces and provides default implementation of the methods. To use these repositories, you have to define your own repository for an entity class by extending Spring Data repositories. For example, to perform database operations on Customer entity class, you can create a CustomerRepository
public CustomerRepository extends CrudRepository<Customer, Integer>{
}
In the above code, CrudRepository interface is provided by Spring Data which accepts the entity class and data type of the identifier attribute of the entity class as generic parameters. This CrudRepository class provides methods to perform different database operations using entity class. Spring Data automatically generates the implementation class at runtime and provides default implementation of methods of CrudRepository interface for CustomerEntity class. S,o you can directly use CustomerRepository in your service classpublic class CustomerServiceImpl implements CustomerService{
@Autowired
CustomerRepository customerRepository;
// add customer details
public void addCustomer(Customer customer){
customerRepository.save(customer);
}
// rest of the methods
}
In the above code, the implementation of save() method is automatically generated to save Customer entity objects.
Similarly, if you have Product entity class, you can define ProductRepository as follows:
public ProductRepository extends CrudRepository<Product,Integer>{
}
So, there is no need to implement the code to perform database operations on Product entity. Now you can see that Spring Data reduces the effort required to develop the persistence layer by avoiding repetitive code. It makes the implementation of persistence layer easier and faster.
What is Spring Data?
Spring Data is a high-level project from Spring whose objective is to unify and ease the access to different types of data access technologies including both SQL and NoSQL databases. It simplifies the data access layer by removing the repository (DAO) implementations entirely from your application. Now, the only artifact that needs to be explicitly defined is the interface.
Core Project provides concepts applicable to all Spring Data projects. It contains Spring Data Commons. It contains interfaces which are technology independent and supports commonly used database operations.
- Sub Projects provide support for most of the data access technologies. Some of the sub projects

CrudRepository Ref
Demo :
@SpringBootApplicationpublic class DemoSpringDataApplication implements CommandLineRunner {
private static final Log LOGGER = LogFactory.getLog(DemoSpringDataApplication.class);@AutowiredCustomerRespository customerRepository;public static void main(String[] args) {SpringApplication.run(DemoSpringDataApplication.class, args);}public void run(String... args) throws Exception {
Customer customer1 = new Customer(2, "monica@infy.com", "Monica", LocalDate.of(1987, 4, 2));Customer customer2 = new Customer(3, "allen@infy.com", "Allen", LocalDate.of(1980, 4, 2));// save customerscustomerRepository.save(customer1);customerRepository.save(customer2);// fetch customer by idLOGGER.info("Customer fetched by findById(1)");LOGGER.info("-------------------------------");Customer customer3 = customerRepository.findById(1).get();LOGGER.info(customer3);// fetching all customersLOGGER.info("Customers fetched by findAll()");LOGGER.info("-------------------------------");Iterable<Customer> customers = customerRepository.findAll();customers.forEach(LOGGER::info);
}
}
Spring Data Repositories :
Spring Data contains repositories which are interfaces using which you can interact with database. We will first discuss about 2 repositories - Repository and CrudRepository.

4. To sort the results by a specified column, you can use OrderBy keyword. By default, results are arranged in ascending order. For example, the following method searches customers by name and also orders the result in ascending order of date of birth:
In above code, "SELECT c.name FROM Customer c WHERE c.emailId = :emailId" is JPQL query with named parameter "emailId". The @Param("emailId") parameter defines the named parameter in the argument list. You can also use positional parameter instead of named parameter
public interface CustomerRespository extends CrudRepository<Customer, Integer> {

1. Repository<T, ID>
- It is core interface of Spring Data Commons and any class which interacts with database using Spring Data must implement this interface.
- It takes the entity class and the data type of its identifier as type arguments.
2. CrudRepository<T, ID>
- It extends Repository interface.
- It takes the entity class and the data type of its identifier as type arguments.
- It provides methods for basic CRUD operations.
- To use it, you need to create an interface by extending CrudRepository. There is no need to write the implementation class as it is automatically generated at runtime.

The methods of CrudRepository are transactional by default. It gets annotated with @Transactional annotation with default values when implementation class is generated at runtime. For read operation, readOnly flag of @Transaction is set to true. You can also override default transactional settings of any of its method by overriding that method in your repository interface and annotating it with @Transactional annotation with required configuration.
Spring Data - Query Approaches
Consider the following entity class and the corresponding repository interface:
@Entity
public class Customer {
@Id
private Integer customerId;
private String emailId;
private String name;
private LocalDate dateOfBirth;
//getters and setters
// toString, hashCode and equals methods
}
public interface CustomerRepository extends CrudRepository<Customer, Integer> {
}
Now, if you need to fetch the details of customer based on emailId, how do you implement?
The methods provided by CrudRepository operate on primary key attribute whereas in this case, emailId is not the primary key.
So, there can be situations and requirements similar to the one discussed here where you will not have methods present in Spring Data repositories.
For implementing these type of requirements, Spring Data provides the following approaches:
- Query creation based on the method name
- Query creation using @Query annotation
- Query creation using @NamedQuery annotation
Query creation based on the method name
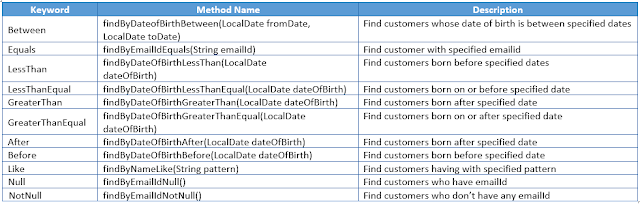
In this approach, we add methods in the interface which extends CrudRepository to implement custom requirements and Spring Data automatically generates the JPQL query based on the name of methods. These methods are called as query methods and are named according to some specific rules. Some basic rules for naming these methods are as follows :
1. The method name should start with "find...By", "get...By", "read...By", "count..By" or "query...By" followed by search criteria. The search criteria is specified using attribute name of entity class and some specified keywords. For example, to search customer based on emailId, the following query method has to be added to repository interface :
Customer findByEmailId(String emailId);
When this method is called, it will be translated to the following JPQL query:
select c from Customer c where c.emailId = ?1
The number of parameters in query method must be equal to number of search conditions and they must be specified in the same order as mentioned in search conditions.
2. To fetch data based on more than one condition, you can concatenate entity attribute names using And and Or keywords to specify search criteria. For example, to search customers based on email address or name , the following method has to be added to repository interface :
List<Customer> findByEmailIdOrName(String emailId, String name);
When the above method is called, it will be translated to following JPQL query:
select c from Customer c where c.emailId = ?1 or c.name=?2
3. Some other keywords that can be used inside query method names are Between, Is, Equals, Not, IsNot, IsNull, IsNotNull, LessThan, LessThanEqual, GreaterThan, GreaterThanEqual, After, Before, Like, etc.
List<Customer> findByNameOrderByDateOfBirth(String name);
List<Customer> findByNameOrderByDateOfBirthDesc(String name);
List<Customer> findByNameOrderByDateOfBirthDesc(String name);
5. To limit the number of results returned by a method, add First or Top keyword before the first 'By' keyword. To fetch more than one result, add the numeric value to the First and the Top keywords. For example, the following methods returns the first 5 customers whose emailId is given as method parameter:
List<Customer> findFirst5ByEmailId(String emailId);
List<Customer> findTop5ByByEmailId(String emailId);
Query creation using @Query annotation
You have learnt how to create JPQL queries using name of query method but for complex requirements, query method names become too long which make them difficult to read and maintain. So, Spring Data provides an option to write custom JPQL queries on repository methods using @Query annotation.
For example, suppose you want to fetch customer name based on emailId, then this requirement can be implemented using @Query annotation
public interface CustomerRepository extends CrudRepository<Customer, Integer> {
//JPQL query
@Query("SELECT c.name FROM Customer c WHERE c.emailId = :emailId")
String findNameByEmailId(@Param("emailId") String emailId);
}
public interface CustomerRepository extends CrudRepository<Customer, Integer> {
//JPQL query
@Query("SELECT c.name FROM Customer c WHERE c.emailId = ?1")
String findNameByEmailId(String emailId);
}
//JPQL query
@Query("SELECT c.name FROM Customer c WHERE c.emailId = ?1")
String findNameByEmailId(String emailId);
}
Executing update and delete queries using @Modifying annotation
You can also execute update, delete or insert operations using @Query annotation. For this, query method has to be annotated with @Transactional and @Modifying annotation along with @Query annotation. For example, the following method updates the emailId of a customer based on customer's customerId.
//JPQL query@Query("UPDATE Customer c SET c.emailId = :emailId WHERE c.customerId = :customerId")@Modifying@TransactionalInteger updateCustomerEmailId(@Param("emailId") String updateCustomerByEmailId, @Param("customerId") Integer customerId);
}
The @Modifying annotation triggers @Query annotation to be used for update or delete or insert operation instead of a select operation.
Query creation using @NamedQuery annotation
learnt how to generate query using query method name and how to define JPQL query using @Query annotation. In these approaches, the queries are scattered across different classes and the same queries may be written in different classes again and again which makes queries difficult to manage.
So, you can use named queries also with Spring Data. The named queries are queries with a name and are defined in entity classes using @NamedQuery annotation. Using Spring Data, default naming strategy of named query is to start with entity class name followed by dot (.) operator and then the name of the invoked repository method. For example, if CustomerEntity is entity class and findNameByEmailId is the name of repository method then query name will be as follows:
Customer.findNameByEmailId
So, you can use named queries also with Spring Data. The named queries are queries with a name and are defined in entity classes using @NamedQuery annotation. Using Spring Data, default naming strategy of named query is to start with entity class name followed by dot (.) operator and then the name of the invoked repository method. For example, if CustomerEntity is entity class and findNameByEmailId is the name of repository method then query name will be as follows:
Customer.findNameByEmailId
Now, to associate JPQL query "SELECT c.name FROM CustomerEntity c WHERE c.emailId = :emailId" with the query name given above, the @NamedQuery annotation
@Entity
@Table(name="customer")
@NamedQuery(name="Customer.findNameByEmailId", query="SELECT c.name FROM Customer c WHERE c.emailId = :emailId")
public class Customer {
@Id
private Integer customerId;
private String emailId;
private String name;
private LocalDate dateOfBirth;
@Enumerated(value=EnumType.STRING)
private CustomerType customerType;
// getter and setter methods
}
To use this named query in a repository, you need to add a query method in repository interface with the same name as defined in named query and the return type of method should be specified according to named query. For example, the following method has to be added to repository to invoke named query CustomerEntity.findNameByEmailId
public interface CustomerRespository extends CrudRepository<Customer, Integer>{
String findNameByEmailId(@Param("emailId") String emailId);
}
Spring Data JPA
Spring Data JPA is one of the sub project of the Spring Data which makes it easy to connect with relational databases using JPA based repositories by extending Spring Data repositories.

JpaRepository<T, ID> interface
- It represents JPA specific repository.
- It inherits methods of CrudRepository and PaginationAndSortingRepository. It also provides some additional methods for batch deletion of records and flushing the changes instantly to database.
- JpaRepository is tightly coupled with JPA persistence technology. So use of this interface as base interface is not recommended. This is generally used used if JPA specific functionalities such as batch deletion and instant flushing of changes to database is required.

JpaSpecificationExecutor interface
- It is not a repository interface.
- It provides methods that are used to fetch entities from database using JPA Criteria API.
Pagination Using SpringBoot
Let us consider one more scenario. Suppose, in a banking application a customer wants to see the details of all transactions performed by him/her. A customer can have hundreds of transactions and displaying all of them in a single page is not advisable. Also, sometimes fetching data of all the transactions at once is time consuming.
It would be much more better if we display the transaction details to the customer in smaller chunks, for example, 10 records per page. This can be implemented by using pagination.
In pagination, all the records are not fetched at same time, rather a subset of records is fetched first and then the next subset of records in fetched if required and so on. This subset of records is called as Page. Every page has two fields – the page number and page size. The page number represents the individual subset of records and page size represents the number of records in a page.
Also, the customers might want to view the transactions in a specific order. For example, the customer might want to view the transactions in increasing order of transaction date. This can be implemented by sorting the records.
Spring Data provides support for pagination and sorting through the PagingAndSortingRepository repository interface.
This interface extends CrudRepository interface and provides the following methods for supporting pagination and sorting:
Page<T> findAll(Pageable pageable)
- This method returns a Page containing entities and accepts a Pageable object as parameter.
- Page interface contains information about the content of the page and some other information such as total number of pages, current page number and whether the current is first page or last page.

Pageable interface contains information about pagination such as size and page number. It is implemented by PageRequest class. You can create its objects using the following methods of PageRequest class:

- Iterable<T> findAll(Sort sort)
- This method returns all the entities in sorted order.
- It accepts object of Sort class as parameter. This object contains information about the fields on which sorting is done and direction of sorting, i.e., ascending or descending.

Sorting Using SpringData
For sorting the transaction details, you need to create the following TransactionRepository interface by extending PagingAndSortingReository interface as follows:public interface TransactionRepository extends PagingAndSortingRepository<Transaction, Integer>{
}
Since this repository is extending PagingAndSortingReository repository, so findAll(Sort sort) is available to this interface for sorting.
The findAll(Sort sort) method accepts object of Sort class as parameter. This class provides different ways to sort data using single and multiple columns and direction of sorting, i.e., ascending or descending using different methods.

- To sort the transaction details using transaction date, you need to first create an object of Sort class using by() method with transactionDate as parameter value and then pass the Sort object to findAll() method
Sort sort = Sort.by("transactionDate");
Iterable<Transaction> transactions = transactionRepository.findAll(sort);
- To sort the details in descending order of transaction date,
Sort sort = Sort.by("transactionDate");
Iterable<Transaction> transactions = transactionRepository.findAll(sort);
- To sort the details in descending order of transaction date,
Sort sort = Sort.by("transactionDate").descending();
Iterable<Transaction> transactions = transactionRepository.findAll(sort);
- To sort by transaction date and then by transaction amount
Sort sort = Sort.by("transactionDate").descending().and(Sort.by("transactionAmount"));
Iterable<Transaction> transactions = transactionRepository.findAll(sort);
Iterable<Transaction> transactions = transactionRepository.findAll(sort);
- To find transaction details after a specific transaction date and sorted based on transaction date along with pagination, then you have to add query method to TransactionRepository
public interface TransactionRepository extends PagingAndSortingRepository<Transaction, Integer>{
public List<TransactionEntity> findByTransactionDateAfter(LocalDate transactionDate, Pageable pageable);
}
- To fetch the details of transactions which are performed after 29-Jan-1996 and sorted based on transaction date with page size = 2,
LocalDate transactionDate = LocalDate.of(1996, 1, 29);
Sort sort = Sort.by("transactionDate");
Pageable pageable = PageRequest.of(0,2,sort);
List<Transaction> transactionList = transactionRepository. findByTransactionDateAfter(transactionDate, pageable);
Sort sort = Sort.by("transactionDate");
Pageable pageable = PageRequest.of(0,2,sort);
List<Transaction> transactionList = transactionRepository. findByTransactionDateAfter(transactionDate, pageable);
PrimaryKey Generation Strategy
Consider a requirement where an admin should be able to add the customer details to the database and customer id should be automatically generated.
To implement this requirement, some mechanism is required so that the primary key gets generated automatically. JPA provides different strategies using which primary key values can be generated automatically.
- IDENTITY strategy
- TABLE strategy
- SEQUENCE strategy
- AUTO strategy
Note: These strategies are not supported by all databases. For example, IDENTITY strategy is not supported by Oracle database because Oracle does not provide identity columns. Similarly, SEQUENCE is not supported by MySQL database because MySQL does not provide support for database sequences

IDENTITY strategy
In this strategy, the value of the primary key is generated using the identity column of the table. The identity column of a table is an integer column having a primary key or unique constraint with the AUTO_INCREMENT feature. For example, in following customer table customer_id is an identity column
CREATE TABLE customer (
customer_id int AUTO_INCREMENT,
email_id varchar(20),
name varchar(10),
date_of_birth date,
constraint ps_customer_id_pk primary key (customer_id)
);
if there are no rows in the table, the starting value of the identity column will be 1, and it will be incremented by 1 for each new row added. If the rows are already present in the table, then the maximum value from the identity column is taken and incremented by 1 to generate the next primary key value.
To use this strategy, the primary key attribute of the entity class is annotated with @GeneratedValue annotation with GenerationType.IDENTITY as the value of the strategy attribute along with @Id annotation
@Entitypublic class Customer{
@Id@GeneratedValue(strategy=GenerationType.IDENTITY)private Integer customerId;// rest of the code
}
When you persist a new Customer entity, JPA selects customer_id column of customer table to generate the primary key value. - If no rows are present in customer table then the generated value of customerId will be 1.
- If rows are already present is customer table then maximum value present in customer_id column will be used for generating value of customerId.
Table Strategy
hibernate_sequences database table is used to generate primary key values:

name of the default table used to generate the primary key values if the TABLE strategy is used : hibernate_sequences
the value in sequence_name column is default and the next_val column contains the value of the primary key. If this table is not present in database you must create it.
To use this strategy, the primary key attribute of entity class is annotated with @GeneratedValue annotation with GenerationType.TABLE as the value of the strategy attribute along with @Id annotation.@Entity
public class Customer{
To use this strategy, the primary key attribute of entity class is annotated with @GeneratedValue annotation with GenerationType.TABLE as the value of the strategy attribute along with @Id annotation.@Entity
public class Customer{
@Id@GeneratedValue(strategy=GenerationType.TABLE)private Integer customerId;//rest of the code
}
When you persist a new Customer entity, JPA generates next primary key value from the value present in next_val column by incrementing it by 1. For example, if the value in the next_val column is 5 then the primary key value generated for customerId will be 6 and the value in the next_val column will be updated to 6.
Table Stratergy Using Column Name
To generate primary key values using table strategy using the default table. But you can also specify your own table for generating primary key values. To do this you have to use @TableGenerator annotation is used along with @GeneratedValue and @Id annotation to define which table has to be used for generating primary key values.
Consider the following id_gen table:

public class Customer{
@Id@TableGenerator(name="pkgen",table="id_gen",pkColumnName="gen_key",valueColumnName="gen_value",pkColumnValue="cust_id",allocationSize=1)@GeneratedValue(generator="pkgen",strategy=GenerationType.TABLE)private Integer customerId;//rest of the code
}
When you persist a new Customer entity, JPA generates next primary key value from the value present in gen_value column by incrementing it by 1. For example, if the value in the gen_value column is 5 and you persist a new Customer entity object then customer details with customerId as 6 will be persisted in the customer table and the value in the gen_value column will be updated to 6.
The @TableGenerator annotation has the following attributes:
- name : It specifies the name of the generator. This name is used to access the generator inside the entity class.
- table : It specifies the name of the table which has to be used for generating primary key values. In our case the table is id_gen.
- pkColumnName : It is the name of the primary key column which contains generator names used for generating primary key value. In our case pkColumnName is gen_key.
- valueColumnName : It is the name of the column which contains the last primary key value generated. In our case valueColumnName is gen_value.
- pkColumnValue : In table, many generators are may be present. This attribute specifies which generator has to be used for generating primary key value among a set of generators in the table. In our case pkColumnValue is cust_id.
- allocationSize : It specifies the amount to increment by when allocating id numbers from the generator.
Sequence Stratergy
@Entity
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE)
private Integer customerId;
// rest of the code
}
no information is provided about which database sequence to use so default Hibernate sequence, hibernate_sequence, is used. This sequence does not come with the database. The developer has to create it.
You can also use a custom database sequence for generating primary key values. For this, you have to define a sequence generator which contains information about database sequence using @SequenceGenerator annotation. Then a reference of this sequence generator is used in @GeneratedValue annotation
@Entity
public class Customer{
@Id
@SequenceGenerator(name="pkgen",sequenceName="customer_sequence",allocationSize=1)
@GeneratedValue(generator="pkgen",strategy=GenerationType.SEQUENCE)
private Integer customerId;
// rest of the code
}
@SequenceGenerator annotation defines a sequence generator with the name "pkgen" which references database sequence named "customer_sequence" and the @GeneratedValue annotation references this using generator attribute. The customer_sequence sequence must be present in the database. If it is not present you must create
Auto Strategy
The persistence provider automatically selects an appropriate strategy for generating primary key values depending on the database used. For example, if Hibernate 5.0 is the persistence provider and MySQL database is used, then this strategy selects the TABLE strategy (hibernate_sequence table) for generating primary key values otherwise it uses SEQUENCE strategy (hibernate_sequence sequence). To use this strategy, the primary key attribute of an entity class is annotated with @GeneratedValue annotation with GenerationType.AUTO as the value of the strategy attribute along with @Id annotation@Entity
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private int customerId;
//rest of the code
}
Association Releationship
class Customer{ class Address{
private Integer customerId; private Integer addressId;
private String customerName; private String doorNumber;
private Address customerAddress; private String city;
//getter and setter methods //getter and setter methods
}
The Customer has a reference of Address class. So you can get the address of a customer if you know customerId. But you cannot get details of a customer if you know addressId because the Address class does not have a reference of Customer class. Such type of relationships is called unidirectional relationship. In these relationships the class which has reference of other class is called as owner or source of the relationship and the class whose reference is present is called a target of the relationship. So here, the Customer is the owner and the Address is the target.
class Customer{ class Address{
private Integer customerId; private Integer addressId;
private String customerName; private String doorNumber;
private Address customerAddress; private String city;
private Customer customer;
//getter and setter methods //getter and setter methods
} }
Cardinality
The cardinality of a relationship defines how many entities exist on each side of the same relationship instance. In our Customer and Address example, one customer can have many addresses, so the cardinality of the Customer side is one, and the Address side is many. On the basis of cardinality, we have the following types of relationships:
- One – to – One Relationship
- One – to – Many Relationship
- Many – to – One Relationship
One – to – One Relationship
As an admin, I should be able to add, update, retrieve, and delete customer and its address details.
A customer can have only one address so you can model this as a one-to-one relationship between Customer and Address entity classes with Customer as owner and Address as a target. To implement this, you can use two tables Customer and Address with Customer table having a foreign key column named address_id that references the Address table as shown below:

@Entity
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer customerId;
private String emailId;
private String name;
private LocalDate dateOfBirth;
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "address_id", unique = true)
private Address address;
//getter and setter
}
@OneToOne(cascade = CascadeType.ALL)
- This annotation specifies that the association relationship has one-to-one multiplicity.
- The cascade attribute specifies operations performed on the owner entity that must be transferred or cascaded to the target entity. It takes values of type CascadeType enumeration. The values of this enumeration are PERSIST, REFRESH, REMOVE, MERGE, DETACH, and ALL. The value ALL specifies that all operations performed on Customer will be cascaded to Address. By default, none of the operations will be cascaded.
@JoinColumn(name = "address_id", unique = true)
- This annotation is used to specify the foreign key column that joins the owner and target entity.
- The name attribute specifies the name of the foreign key column in the table mapped to the owner entity.
- The unique = true assures that unique values will be stored in the join column.
Many – to – One Relationship
sanction multiple loans to a customer.A customer can have multiple loans such as car loan, home loan etc. so you can model this as a many-to-one relationship between Customer and Loan entity classes with Loan as an owner of the relationship. To implement, you can use two tables Customer and Loan. The Loan table has a foreign key column named cust_id that references the Customer table

reference of Customer entity class in annotated with @ManyToOne annotation which declares that there is many-to-one relationship between Customer and Loan. The @JoinColumn annotation is used to define the name of the foreign key column in the Customer table that links the customer to the card.
@Entity
public class Customer {
public class Customer {
@Idprivate Integer customerId;@Column(name="emailid")private String emailId;private String name;private LocalDate dateOfBirth;//getter and setter methods
}
@Entity
public class Loan{
@Entity
public class Loan{
@Id@GeneratedValue(strategy=GenerationType.IDENTITY)private Integer loanId;private Double amount;private LocalDate issueDate;private String status;@ManyToOne(cascade=CascadeType.ALL)@JoinColumn(name="cust_id")private Customer customer;//getter and setter methods
}
@ManyToOne(cascade = CascadeType.ALL)
- This annotation indicates that the relationship has many-to-one cardinality.
- The cascade attribute tells which operation (such as insert, update, delete) performed on source entity can be transferred or cascaded to target entity. By default, none of the operations will be cascaded. It takes values of type CascadeType enumeration. The value ALL means all operations will be cascaded from source to target. Other values of this enumeration are PERSIST, REFRESH, REMOVE, MERGE, and DETACH.
@JoinColumn(name = "cust_id")
- This annotation is used to define the name of the foreign key column that joins the owner and target entity.
- The name attribute specifies the name of the foreign key column in the table mapped to the source entity.
One – to – Many Relationship
Issue multiple cards to the customer.
A customer can have multiple cards so you can model this as one-to-many relationship between Customer and Card entity classes with Customer entity as owner. To implement this user story, you can use two tables Customer and Card. The Card table has a foreign key column named cust_id which references the Customer table

@Entity
public class Card {
@Id
private Integer cardId;
private String cardNumber;
private LocalDate expiryDate;
// getter and setter methods
}
@Entity
public class Customer{
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer customerId;
private String emailId;
private String name;
private LocalDate dateOfBirth;
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="cust_id")
private List<Card> cards;
//getter and setter methods
}
List<Card> in annotated with @OneToMany annotation which declares that there exists a one-to-many relationship between Customer and Card entity classes. The @JoinColumn annotation is used to give the name of a foreign key column in Card table which links the customer to the card. You can also use Set<Card> instead of List<Card>. Now let us understand these annotations in detail:
@OneToMany(cascade = CascadeType.ALL)
- This annotation indicates that the relationship has one-to-many cardinality.
- The cascade attribute tells which operation (such as insert, update, delete) performed on the source entity can be transferred or cascaded to the target entity. By default, none of the operations will be cascaded. It takes values of type CascadeType enumeration. The value ALL means all operations will be cascaded from source to target. Other values of this enumeration are PERSIST, REFRESH, REMOVE, MERGE, and DETACH.
@JoinColumn(name = "cust_id")
- This annotation is used to specify the join column using its name attribute. The target entity is mapped to the Customer table which has cust_id as the foreign key column, so the name is cust_id.
Many – to – Many Relationship
provide multiple services to the customers.
A customer can avail multiple services such as internet banking, phone banking etc and one type of service can be availed by multiple customers so we can model this as a many-to-many association between CustomerEntity and ServiceEntity classes with CustomerEntity as the source.
To implement this user story, we need three tables CUSTOMER, SERVICE and CUSTOMER_SERVICE. The CUSTOMER table is mapped to Customer entity class and SERVICE table is mapped to Service entity class. The CUSTOMER_SERVICE table is used to define the many-to-many relationship. This table is called a Join Table and has foreign key columns that store the many-to-many association

public class Customer{
@Id@GeneratedValue(strategy=GenerationType.IDENTITY)private Integer customerId;@Column(name="emailid")private String emailId;private String name;private LocalDate dateOfBirth;@ManyToMany(cascade=CascadeType.ALL)@JoinTable(name="customer_service",joinColumns=@JoinColumn(name="cust_id"),inverseJoinColumns=@JoinColumn(name="serv_id"))private Set<Service> bankServices;
}
Set<Service> in annotated with @ManyToMany annotation which declares that there is a many-to-many relationship between Customer entity class and Service entity class. The @JoinColumn annotation is used to define the name of the join table and foreign key columns that store the many-to-many association. You should always use a Set instead of a List while implementing many to many associations. This is because JPA uses a very inefficient approach to remove entities from the association where it removes all records from the association table and re-insert the remaining ones.
Now let us understand these annotations in detail:
@ManyToMany(cascade = CascadeType.ALL)
- This annotation indicates that the relationship has many-to-many cardinality.
- The cascade attribute tells which operation (such as insert, update, delete) performed on source entity can be transferred or cascaded to target entity. By default, none of the operations will be cascaded. It takes values of type CascadeType enumeration. The value ALL means all operations will be cascaded from source to target. Other values of this enumeration are PERSIST, REFRESH, REMOVE, MERGE and DETACH.
@JoinTable(name="customer_service", joinColumns=@JoinColumn(name="cust_id"),inverseJoinColumns=@JoinColumn(name="serv_id"))
- This annotation is used to define the join table.
- The name attribute specifies the name of the join table.
- The joinColumns are foreign key columns of the join table which references the columns of the table mapped with the source entity of the association. The joinColumns are given using @JoinColumn annotation whose name attribute specifies the name of column in join table which is mapped with primary key column of the table mapped with the source entity.
- The inverseJoinColumns are foreign key columns of the join table which references the columns of the table mapped with the target entity of the association. The inverseJoinColumns are given using @JoinColumn annotation whose name attribute specifies the name of column in join table which is mapped with primary key column of the table mapped with the target entity.
SpringJDBC
Challenges in using JDBC
You have already learned how to use JDBC for data access. But using JDBC is challenging because of following reasons:
- Connection Management : In JDBC you have to write code for managing connections. If connections are not managed properly then application performance gets impacted.
- Exception Handling : The JDBC code throws SQLException which is a checked exception. So you have to write code to handle them even though database errors are mostly unrecoverable. Also, inappropriate handling of SQLException leads to many other problems.
- Code Duplication : In JDBC lot of repetitive code is written to perform operations such as obtaining database connection, creating a statement, converting data obtained as rows and columns into objects etc. Because of this lot of time is spent in writing data persistence rather business logic. This effects project costs, efforts, and timelines.
So to make use of JDBC easier Spring provided one layer of abstraction, called Spring JDBC
Spring JDBC
Spring provides support for JDBC through Spring JDBC. It is a layer of abstraction on JDBC which makes use of JDBC easier and helps to avoid common errors. It consists of following four packages :
- org.springframework.jdbc.core – It contains core JDBC classes JdbcTemplate, SimpleJdbcCall, NamedParameterJdbcTemplate, and SimpleJdbcInsert.
- org.springframework.jdbc.datasource – It contains utility classes to access database and different implementation classes of DataSource.
- org.springframework.jdbc.object – It contains classes to access database in an object-oriented manner. It allows executing queries and returning the results as a model object. It also maps the query results between the columns and properties of objects.
- org.springframework.jdbc.support – It contains support classes for core and object packages and provides facility for SQLException translation.
The JdbcTemplate is core class of Spring JDBC
JdbcTemplate
JdbcTemplate is the main class of Spring JDBC. It makes use of JDBC easy in following ways:
- It takes care of opening and closing of connections, so you need not to write the code for managing them.
- It provides various overloaded methods for executing SQL queries and handling results as different types of objects.
- It catches JDBC exceptions and translates them to more generic and informative exception.
It provides several overloaded methods to execute SQL queries. Some methods of this class are as follows:
- update() - This method is used for executing INSERT, UPDATE and DELETE queries.
- query() - This method is used for executing SELECT queries which can return multiple rows.
- queryForObject() - This method is used for executing SELECT queries which returns a single row.
package com.infy.repository;
import java.sql.Date;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.dao.EmptyResultDataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
import com.infy.dto.CustomerDTO;
@Repository(value = "customerRepository")
public class CustomerRepositoryImpl implements CustomerRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
public void addCustomer(CustomerDTO customerDTO) {
String query = "insert into customer (customer_id, emailid, name, date_of_birth) values (?,?,?,?)";
jdbcTemplate.update(query, customerDTO.getCustomerId(), customerDTO.getEmailId(), customerDTO.getName(),Date.valueOf(customerDTO.getDateOfBirth()));
}
public CustomerDTO getCustomer(Integer customerId) {
String query = "select * from customer where customer_id = ?";
try {
return jdbcTemplate.queryForObject(query, new Object[] { customerId }, new CustomerRowMapper());
} catch (EmptyResultDataAccessException e) {
return null;
}
}
public String getCustomerName(Integer customerId) {
String query = "select name from customer where customer_id = ?";
try {
return jdbcTemplate.queryForObject(query, new Object[] { customerId }, String.class);
} catch (EmptyResultDataAccessException e) {
return null;
}
}
public List<CustomerDTO> getAllCustomers() {
String query = "select * from customer";
return jdbcTemplate.query(query, new CustomerRowMapper());
}
public void updateCustomer(Integer customerId, String emailId) {
String query = "update customer set emailid = ? where customer_id = ?";
jdbcTemplate.update(query, emailId, customerId);
}
public void deleteCustomer(Integer customerId) {
String query = "delete from customer where customer_id = ?";
jdbcTemplate.update(query, customerId);
}
}





